How we compiled a single dataset containing speeches given in the Greek Parliament plenary sessions between 1989 and 2020, as well as data on the MPs who addressed them.
The aim was to create a single dataset using all kinds of speeches (addresses, statements, interventions, etc.) that have been delivered at the plenary sessions of the Greek Parliament between 1989 and 2020, providing information regarding: a) the speaker – their status, their gender, their constituency, the political party they belonged to at the time of speech, etc. and b) the context of each speech at the time delivered – data regarding parliamentary term, sitting date, ruling party, etc.
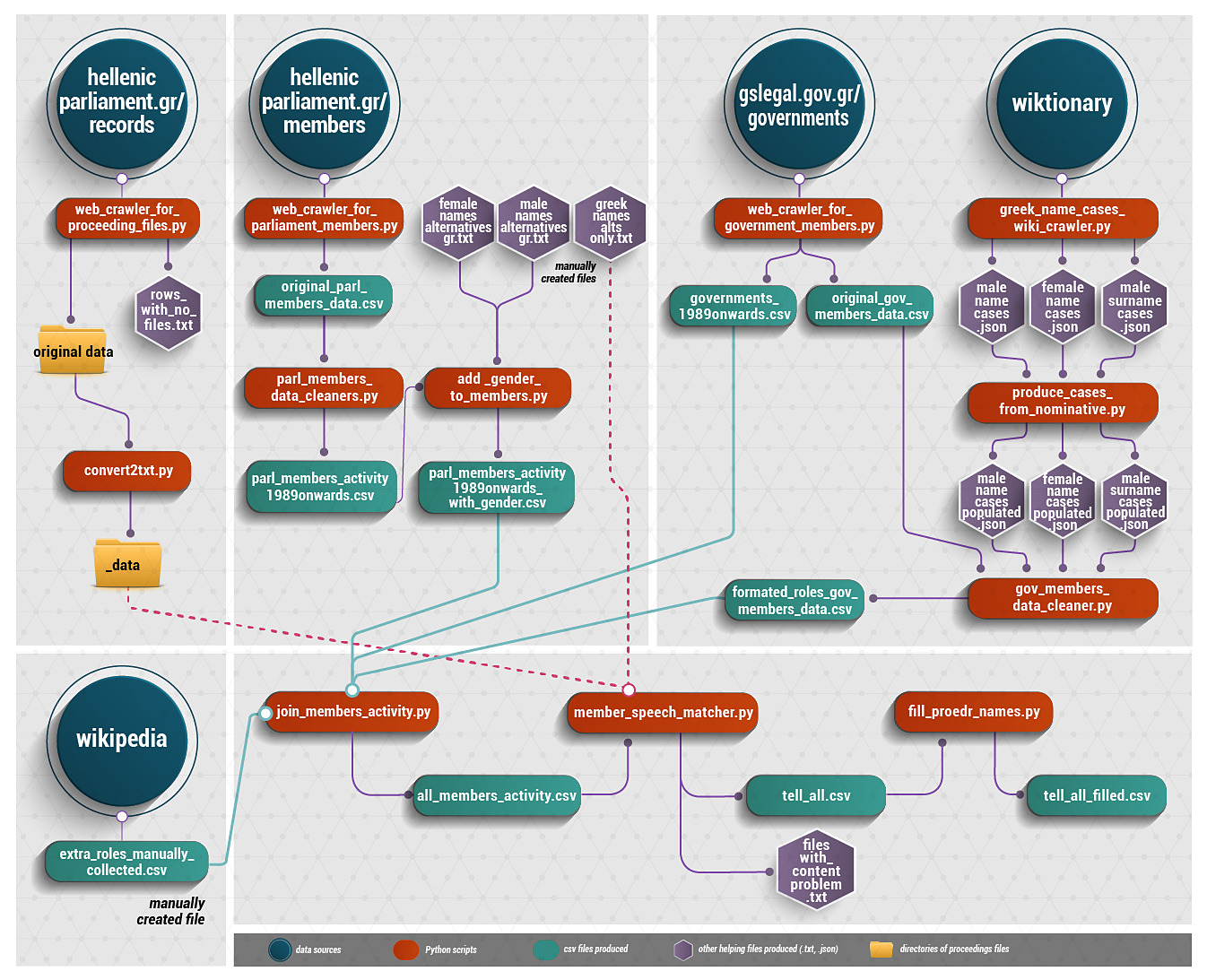
The entire project1 was realized using the Python programming language and utilizing and combining available data from multiple sources.
Parliamentary minutes from 1989 until today

Speeches delivered at the plenary sessions of the Greek Parliament during the last 31 years, speakers, and speaker roles
Data collection
Using the Selenium and BeautifulSoup4 libraries, we collected all minutes of plenary sittings that were digitally available and had been published on the Parliament’s website. These date from July 3, 1989 onwards – more specifically, in order to compile the dataset, we retrieved minutes (5,355 files) of sittings extending until July 24, 2020. Data collection was carried out gradually and in stages , until August 2020.
Parliament publishes minutes in various document formats (.pdf, .docx, .doc and .txt files) or in html format. The Apache Tika toolkit (tika-app-1.20.jar) was used to convert documents to a single, editable format (.txt files), while the BeautifulSoup4 library was used to extract texts from the Parliament’s html webpages. A number of parliamentary minutes were publicly available only in .pdf format and contained encodings of Greek characters that were unreadable by Apache Tika. This problem could be addressed in a future project through the use of OCR (Optical Character Recognition) technology. The aforementioned texts – which are 121 minutes of sittings, dating mainly to 1998, 2002 and 2003 – are not included in the present work and they have not been taken into account. Also, for an additional 12 sittings, minutes were not posted online.
Using the Selenium and BeautifulSoup4 libraries, we also collected:
- official information on the term of office of elected members of Parliament, as available on Parliament’s website under the relevant section, titled “term of office of MPs from 1974 until today” – including constituencies;
- information on governments from 1989 to 2020, as published on the website of the General Secretariat of Legal and Parliamentary Issues, under the section “Governments from 1909 to the present” – in this way, we were able to retrieve data on each government member, elected or otherwise, who had assumed a parliamentary role during the study period, including the start and end dates of that role.
Further, information on additional roles of Members of Parliament (e.g. Speaker/Vice-Speaker of Parliament, or party leader), which was not available in an institutional source as consolidated information, was obtained, on a case-by-case basis, through personal research by our research group. For instance, information regarding a Speaker’s term start and finish dates was posted after searching for the corresponding Wikipedia entry and cross-referencing with information from the vouliwatch.gr website, as well as from the incomplete list of former Speakers on the Parliament’s website – as an indicative example, Wikipedia entries for the current and former Speaker of the Parliament (Kostas Tasoulas and Nikos Voutsis, respectively) have been listed.
Lists of female/male names and male surnames included in the Greek version of Wiktionary. Following further research, those lists were appended with more names and nicknames that were added by the working team. Among other things, these lists served, at a later stage, to identify Members of Parliament, who were often mentioned in an unsystematic way in the Parliament’s sittings’ minutes.
Data cleaning and processing
After data collection was completed, two different datasets were created: one with speeches extracted from the minutes of sittings and one with the data on the activity of parliamentary and government members. In each of them, data cleaning was required and corrections had to be made. The following are some indicative examples:
- Descriptions of physical and non-verbal events included in the minutes have been removed: for example, a parliamentary reporter may make a note when applause breaks out from a particular party wing or when someone enters the room.
- Regarding the contextual elements of the each Plenary (period, session, sitting), in order for the data to be more easily editable by the research group and any prospective researcher: a) the information was translated into English, b) the ( Ionic) Greek system of numeration was converted to the Hindu-Arabic numeral system. For instance, the current “Period ΙΗ’ Review Θ’” was rendered as “period 18 review 9”. Also, the indication “review” was added in cases of Revisionary Parliament assembly, when the latter was not included in the provided sittings’ minutes, but was noted in the election results list on the Parliament’s website.
- Mentions of parties and constituencies were systematized by introducing homogenized writing in each case.
- Names of government members written in the genitive case on the General Secretariat of Legal and Parliamentary Issues website (as in this example) were converted to the nominative case with the help of Wiktionary data.
- Speakers’ gender was determined based on their names and with the auxiliary use of data from the Wiktionary and the supplementary list created by the working team.
- The start and end dates of each government’s term of office were required to process data. Since the start date of a government term coincides with the end date of the previous one, the start date for each new government was preserved in the dataset and it is assumed that the previous government completed its term on the date immediately prior to that, which is considered as the end date of the outgoing government.
- For the purposes of data processing, the inclusion of start and end dates of the governmental role of each government member was necessary. However, the source’s primary data does not include any entries on the end of term of some government members. In such cases, the government member’s end of term is considered to coincide with the date the government left office.
- Regarding the roles of government officials, the following were identified on the same website and subsequently transcribed:
- In some cases, government officials are assigned two roles merged into one. For example, an executive was appointed as “Minister of National Economy and Tourism” (see caretaker cabinet of Ioannis Grivas, appointment of Georgios Kontogeorgis as “Minister of National Economy and Tourism”, and resignation of “Minister of National Economy and Minister of Tourism” Georgios Kontogeorgis). During data processing, the government official was assigned these two roles (Minister of National Economy and Minister of Tourism) separately.
- Since, during a ministerial term, a ministry can be renamed, there were entries of government officials who had seemingly “resigned” from a ministry in order to take their post at the newly renamed one. For the purposes of the dataset, we chose to retain ministry names at the time executives took office.
- Any errors detected on the same website upon entering data have been corrected. For instance, on the current government’s webpage, Panagiotis Mitarakis appears to have resigned as Deputy Minister of Labor and Social Affairs on January 15, 2020. He also appears to have resigned as Minister of Migration and Asylum on the same date, when in fact he was appointed as such (see Government Gazette A’ 5 / 15-1-2020).
- During the Konstantinos Mitsotakis administration, the title Ministers without Portfolio assumed the guise of Ministers of State, by Law 1943/1991. In this case, the research group assigned both roles to the respective government officials, providing information on the respective start and end dates of each term. The date of publication of Law 1943/1991 (April 11, 1991) was set as the commencement date of the “Minister of State” role for the relevant executives.
Assigning speakers to speeches
Drawing on the collected minutes, we managed to find out the identity of each speaker, based on the record of their name, as it was written to introduce their speech.
For each speaker x we identified in the sittings’ minutes:
- we referred to the date of the minutes of the sitting,
- from the second set of data on the activity of parliamentary and government executives, we retrieved only the names of those members who appear to have been active on the reporting date – thus focusing on a subset of candidates,
- using the jellyfish library and, in particular, the Jaro-Winkler Similarity method, we compared each name of this subset with the name of speaker x, which was previously extracted from the minutes of the sitting: in cases where the similarity percentage between two names was greater than 95%, we attributed the speech to the official executive, as they appear our dataset regarding members and their activity.
Code snippet for assigning names
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40temp_max = 0 # put these transpositions in the beginning, before we remove '-' # If member has more than one first names if '-' in member_name: # there are cases like member name being δενδιας νικολαος-γεωργιος # and detected speaker being ΝΙΚΟΛΑΟΣ ΔΕΝΔΙΑΣ # if member has two first names if len(member_name.split('-'))==2: member_name1, member_name2 = member_name.split('-') # if member has three first names elif len(member_name.split('-'))==3: member_name1, member_name2, member_name3 = member_name.split('-') # if member has more than one first names and one surname if '-' not in member_surname: # do the following for two first names sim5 = jellyfish.jaro_winkler_similarity(speaker_name, member_name1+' '+member_surname) sim6 = jellyfish.jaro_winkler_similarity(speaker_name, member_surname+' '+member_name1) sim7 = jellyfish.jaro_winkler_similarity(speaker_name, member_name2+' '+member_surname) sim8 = jellyfish.jaro_winkler_similarity(speaker_name, member_surname+' '+member_name2) temp_max = max(temp_max, sim5, sim6, sim7, sim8) # Extra comparisons for alternative names of members temp_max = compare_with_alternative_sim(speaker_name, member_name1, member_surname, temp_max, greek_names) temp_max = compare_with_alternative_sim(speaker_name, member_name2, member_surname, temp_max, greek_names) # do the following extra for three first names # for example κουικ φιλιππου τερενς-σπενσερ-νικολαος if len(member_name.split('-'))==3: sim9 = jellyfish.jaro_winkler_similarity(speaker_name, member_name3+' '+member_surname) sim10 = jellyfish.jaro_winkler_similarity(speaker_name, member_surname+' '+member_name3) temp_max = max(temp_max, sim9, sim10) # Extra comparisons for alternative names of members temp_max = compare_with_alternative_sim(speaker_name, member_name3, member_surname, temp_max, greek_names)
Speakers are not always recorded in the minutes following the same pattern: for example, a surname may either precede or follow a name, a first name may have been replaced by a diminutive, or the speaker may be referred to by his full name, followed by a diminutive, by which they are most famously known as, in brackets. Finally, some persons with more than one name or surname may be referred to by either one of them. Since the Jaro-Winkler metric takes into account the order of letters in order to compare two words, the names “Fotini Gennimata” and “Gennimata Fotini” would have zero similarity, for example. Similarly, the names “Fofi Gennimata”, “Fotini Gennimata”, “Fotini-Fofi Gennimata”, which refer to the same person, do not match. For this reason, for each comparison between an identified speaker and an official name of a parliamentary or government executive, we created all possible variations of an official name, alternating the order of the words that make up that name and replacing or combining the name with its diminutives. We then calculated the degree of similarity between all possible pairs and chose the one with the highest degree.
The research team looked for cases of namesake in the official list of parliamentary and government executives, but did not identify any within the same period of office.
Cases of missing information in the minutes were treated as follows:
- If it was possible to link the speech to a particular role (for example, that of “president” or “witness”), without being able to assign it to a name, then the speech was preserved in the dataset – with a blank value in the speaker.
- When it was not possible to assign the speech to a specific person or, at least, to a specific role, then the speech was deleted and is not included in the dataset. Such cases have arisen due to inconsistent / unsystematic formatting in passages of certain minutes.
1 This dataset is produced on behalf of iMEdD, as part of the pillar of Lab, by PhD Student in Machine Learning Konstantina Dritsa (producer), with the contribution of data journalist and iMEdD Lab Project Manager Kelly Kiki. The methodology for the collection of the parliamentary minutes and for the processing of data originated from the work implemented during the course of the Master thesis entitled “Speech quality and sentiment analysis on the Hellenic Parliament proceedings” at the Athens University of Economics & Business in 2018 under the supervision of the Associate Professor Panagiotis Louridas.
Translation: Anatoli Stavroulopoulou
Graphic design: Evgenios Kalofolias