Πώς συγκροτήσαμε ένα ενιαίο σύνολο δεδομένων, με τις ομιλίες στις συνεδριάσεις της Ολομέλειας στη Βουλή από το 1989 ως το 2020, και με στοιχεία για τους βουλευτές που τις απεύθυναν.
Στόχος ήταν να δημιουργήσουμε ένα ενιαίο σύνολο δεδομένων (dataset), με κάθε είδους ομιλίες (λόγοι, τοποθετήσεις, παρεμβάσεις κ.ο.κ.) που έχουν εκφωνηθεί σε συνεδριάσεις της Ολομέλειας στο ελληνικό Κοινοβούλιο, από το 1989 έως το 2020, αντιστοιχίζοντας καθεμία από αυτές με: α) τον ομιλούντα και βασικές πληροφορίες για τον ίδιο, όπως η ιδιότητά του, το φύλο του, η εκλογική περιφέρειά του, το πολιτικό κόμμα στο οποίο ανήκε τη στιγμή των λεγομένων του κλπ, β) βασικά στοιχεία για το πλαίσιο εκφοράς της εκάστοτε ομιλίας, όπως η κοινοβουλευτική περίοδος, η ημερομηνία της συνεδρίασης, η κυβέρνηση κλπ.
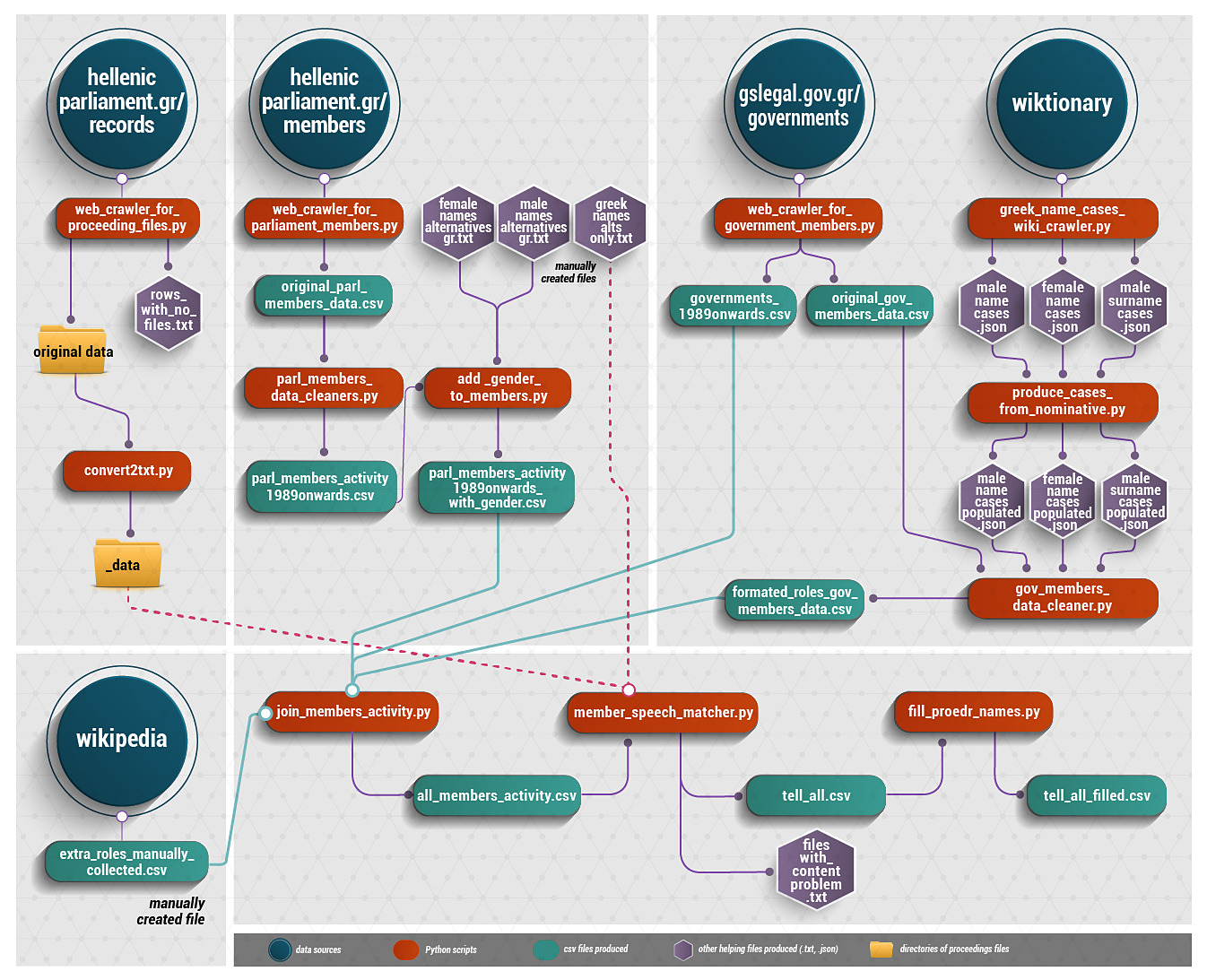
Το έργο1 έγινε εξ ολοκλήρου με τη χρήση της γλώσσας προγραμματισμού Python και με την αξιοποίηση και τον συνδυασμό διαθέσιμων δεδομένων από πολλαπλές πηγές.
Τα πρακτικά της Βουλής από το 1989 ως σήμερα

Οι ομιλίες που έχουν εκφωνηθεί στις συνεδριάσεις της Ολομέλειας στο ελληνικό Κοινοβούλιο τα τελευταία 31 χρόνια, οι ομιλούντες και τα στοιχεία της ιδιότητάς τους.
Συλλογή δεδομένων
Με τη χρήση των βιβλιοθηκών Selenium και BeautifulSoup4, συγκεντρώσαμε όσα πρακτικά συνεδριάσεων της Ολομέλειας είναι ψηφιακά διαθέσιμα και διαδικτυακά δημοσιευμένα στην ιστοσελίδα του Κοινοβουλίου. Αυτά χρονολογούνται από τις 3 Ιουλίου 1989 και εφεξής –συγκεκριμένα, στο πλαίσιο δημιουργίας του συγκεκριμένου dataset, ανακτήθηκαν πρακτικά συνεδριάσεων (5.355 αρχεία) τα οποία εκτείνονται χρονικά ως τις 24 Ιουλίου 2020. Η συλλογή των δεδομένων έγινε σταδιακά και τμηματικά, ως τον Αύγουστο 2020.
Το Κοινοβούλιο διαθέτει διαδικτυακά τα εν λόγω πρακτικά σε διαφορετικές μορφές εγγράφων (αρχεία .pdf, .docx, .doc και .txt) ή σε μορφή html. Για τη μετατροπή των εγγράφων σε μία ενιαία μορφή (αρχεία .txt), επεξεργάσιμη από ηλεκτρονικό υπολογιστή, χρησιμοποιήθηκε η εργαλειοθήκη Apache Tika (tika-app-1.20.jar), ενώ για την εξαγωγή του κειμένου από τις html σελίδες του Κοινοβουλίου χρησιμοποιήθηκε η βιβλιοθήκη BeautifulSoup4. Υπήρξε μία σειρά πρακτικών της Βουλής, που είναι δημοσίως διαθέσιμα μόνο σε αρχεία .pdf και τα κείμενα των οποίων φέρουν διαφορετικές μη δημοφιλείς κωδικοποιήσεις των ελληνικών χαρακτήρων, μη αναγνωρίσιμες με τη χρήση Apache Tika. Τα συγκεκριμένα αρχεία ενδεχομένως θα μπορούσαν, σε μελλοντική εξέλιξη του έργου, να αντιμετωπιστούν με τεχνολογία OCR («Optical Character Recognition»). Στο παρόν έργο, δεν περιλαμβάνονται και δεν λαμβάνονται υπόψη. Πρόκειται για 121 αρχεία πρακτικών, τα οποία χρονολογούνται κυρίως το 1998, το 2002 και το 2003. Ακόμη, για επιπλέον 12 συνεδριάσεις δεν βρέθηκαν τα πρακτικά αναρτημένα διαδικτυακά.
Επίσης με τη χρήση των βιβλιοθηκών Selenium και BeautifulSoup4, συλλέξαμε:
- επίσημα στοιχεία για τη θητεία εκλεγμένων μελών του Κοινοβουλίου, όπως αυτά διατίθενται στην ιστοσελίδα του Κοινοβουλίου, στη σχετική ενότητα για τους διατελέσαντες βουλευτές από τη Μεταπολίτευση ως σήμερα –περιλαμβανομένης εκλογικής περιφέρειας,
- πληροφορίες για τις κυβερνήσεις από το 1989 ως το 2020, όπως είναι δημοσιευμένες στον ιστότοπο της Γενικής Γραμματείας Νομικών και Κοινοβουλευτικών Θεμάτων, στην ενότητα Κυβερνήσεις από το 1909 ως σήμερα –κατ’ αυτόν τον τρόπο, ανακτήθηκαν στοιχεία για κάθε μέλος κυβερνητικού σχήματος, εκλεγμένου ή μη, το οποίο είχε κοινοβουλευτικό ρόλο κατά το χρονικό διάστημα μελέτης, περιλαμβανομένων των ημερομηνιών έναρξης και λήξης του ρόλου αυτού.
Συμπληρωματικά, πληροφορίες για πρόσθετους ρόλους μελών του Κοινοβουλίου (για παράδειγμα, πρόεδρος/αντιπρόεδρος της Βουλής, αρχηγός κόμματος), οι οποίοι δεν βρέθηκαν διαθέσιμοι σε κάποια θεσμική πηγή ως ενοποιημένη πληροφορία, αντλήθηκαν, κατά περίπτωση, με προσωπική έρευνα και καταχωρήθηκαν από την ομάδα εργασίας. Για παράδειγμα, πληροφορίες για την έναρξη και λήξη του ρόλου ενός μέλους ως προέδρου της Βουλής καταχωρήθηκαν, κατόπιν αναζήτησης στις αντίστοιχες σελίδες της Wikipedia και διασταύρωσης με πληροφορίες από την ιστοσελίδα vouliwatch.gr, καθώς και από την ελλιπή λίστα διατελεσάντων προέδρων στην ιστοσελίδα της Βουλής –ενδεικτικά, παρατίθενται οι σελίδες της Wikipedia για τους νυν και προηγούμενο πρόεδρο της Βουλής, Κώστα Τασούλα και Νίκο Βούτση αντίστοιχα.
Ως βοηθητικές πηγές δεδομένων χρησιμοποιήθηκαν οι λίστες θηλυκών και αρσενικών ονομάτων, όπως και αρσενικών επωνύμων, που παρέχονται για τα νέα ελληνικά στο Wiktionary. Στη συνέχεια, κατόπιν περαιτέρω έρευνας από την ομάδα εργασίας, αυτές εμπλουτίστηκαν με κύρια ονόματα και με υποκοριστικά ονομάτων, τα οποία καταχωρήθηκαν από την ομάδα εργασίας. Μεταξύ άλλων, οι λίστες αυτές χρησίμευσαν, σε μεταγενέστερο στάδιο, στην ταυτοποίηση των βουλευτών, οι οποίοι συχνά αναφέρονται με μη συστηματοποιημένο τρόπο στα πρακτικά τον συνεδριάσεων.
Καθαρισμός και επεξεργασία δεδομένων
Μετά τη συλλογή των στοιχείων, είχαν δημιουργηθεί δύο διαφορετικά σύνολα δεδομένων: ένα με τις ομιλίες οι οποίες είχαν εξαχθεί από τα πρακτικά των συνεδριάσεων και ένα με τα στοιχεία για τη δραστηριότητα των κοινοβουλευτικών και κυβερνητικών μελών. Σε καθένα από αυτά, χρειάστηκε να γίνουν καθαρισμός και διορθώσεις δεδομένων. Ενδεικτικά, αναφέρονται παρακάτω μερικά παραδείγματα χαρακτηριστικών περιπτώσεων:
- Αφαιρέθηκαν σκηνικές περιγραφές που παρατίθενται στα πρακτικά: για παράδειγμα, πρακτικογράφος μπορεί να σημειώνει ότι ακούγονται χειροκροτήματα από πτέρυγα συγκεκριμένου κόμματος ή ότι κάποιος εισέρχεται στην αίθουσα.
- Όσον αφορά στα στοιχεία πλαισίου της εκάστοτε Ολομέλειας (κοινοβουλευτική περίοδος, σύνοδος, συνεδρίαση), προκειμένου τα δεδομένα να είναι πιο εύκολα επεξεργάσιμα από την ομάδα εργασίας και από κάθε πιθανό μελλοντικό ερευνητή: α) οι πληροφορίες μεταφράστηκαν στην αγγλική γλώσσα, β) το (ιωνικό) ελληνικό σύστημα αρίθμησης μετατράπηκε σε ινδο-αραβικό σύστημα αρίθμησης. Έτσι, για παράδειγμα, η τρέχουσα «ΙΗ’ Περίοδος Θ’ Αναθεωρητική» αποδόθηκε ως «period 18 review 9». Επίσης, προστέθηκε το διακριτικό «review» σε περιπτώσεις Αναθεωρητικής Βουλής η οποία δεν επισημαίνεται στον παρεχόμενο κατάλογο με τα πρακτικά των συνεδριάσεων, αλλά σημειώνεται στη λίστα των εκλογικών αποτελεσμάτων στην ιστοσελίδα του Κοινοβουλίου.
- Συστηματοποιήθηκε ο τρόπος αναφοράς κομμάτων και εκλογικών περιφερειών, ορίζοντας μία ομογενοποιημένη γραφή ανά περίπτωση.
- Όσον αφορά στα ονόματα των κυβερνητικών μελών, η γενική πτώση στην οποία αναφέρονται στην ιστοσελίδα της Γενικής Γραμματείας Νομικών και Κοινοβουλευτικών Θεμάτων (παράδειγμα σελίδας για κυβέρνηση) μετατράπηκε σε ονομαστική πτώση, με τη βοηθητική χρήση δεδομένων από το Wiktionary.
- Αποδόθηκε το φύλο των ομιλούντων, με βάση τα ονόματά τους και με τη βοηθητική χρήση δεδομένων από το Wiktionary και την πρόσθετη λίστα που καταρτίστηκε από την ομάδα εργασίας.
- Για την επεξεργασία των δεδομένων, ήταν απαραίτητες ημερομηνίες έναρξης και λήξης της θητείας κάθε κυβέρνησης. Δεδομένου ότι η ημερομηνία έναρξης μιας κυβερνητικής θητείας συμπίπτει με την ημερομηνία λήξης της θητείας κάθε προηγούμενης κυβέρνησης, επιλέχθηκε η ημερομηνία έναρξης θητείας για την εκάστοτε νέα κυβέρνηση να διατηρηθεί ως τέτοια στο dataset και να φέρεται ότι η προηγούμενη κυβέρνηση ολοκλήρωσε τη θητεία της την αμέσως προηγούμενη ημερομηνία, η οποία αποδίδεται ως ημερομηνία λήξης της εκάστοτε απερχόμενης κυβέρνησης.
- Για τους σκοπούς της επεξεργασίας των δεδομένων, η ενσωμάτωση ημερομηνιών έναρξης και λήξης του κυβερνητικού ρόλου κάθε μετέχοντα σε κυβερνητικό σχήμα ήταν απαραίτητη. Ωστόσο, στα πρωτογενή δεδομένα της πηγής, κάποιες φορές, εντοπίστηκε να μην υπάρχουν καταχωρήσεις για τη λήξη της θητείας ορισμένων μελών κάποιων κυβερνήσεων. Στην περίπτωση αυτή, ως ημερομηνία λήξης της θητείας του μέλους στο κυβερνητικό σχήμα, ορίστηκε η ημερομηνία λήξης της κυβερνητικής θητείας εν συνόλω.
- Ως προς τους ρόλους των κυβερνητικών στελεχών, στην ίδια ιστοσελίδα, εντοπίστηκαν και μεταγράφηκαν τα εξής:
- Σε ορισμένες περιπτώσεις στελεχών κάποιων κυβερνήσεων, αποδίδονται δύο ρόλοι ως ένας. Για παράδειγμα, εντοπίστηκε εγγραφή στελέχους με τον ρόλο «Υπουργός Εθνικής Οικονομίας και Τουρισμού» (βλ. υπηρεσιακή κυβέρνηση Ιώαννη Γρίβα, διορισμός Γεώργιου Κοντογεώργη ως «Υπουργού Εθνικής Οικονομίας και Τουρισμού», παραίτηση του ιδίου ως «Υπουργού Εθνικής Οικονομίας και Υπουγού Τουρισμού»). Τότε, στο πλαίσιο της επεξεργασίας των δεδομένων, αποδόθηκαν στο κυβερνητικό στέλεχος οι δύο διαφορετικοί ρόλοι ξεχωριστά, «Υπουργός Εθνικής Οικονομίας» και «Υπουργός Τουρισμού».
- Δεδομένου ότι, κατά τη διάρκεια μιας υπουργικής θητείας, ένα υπουργείο μπορεί να μετονομαστεί, υπήρξαν καταχωρήσεις κυβερνητικών στελεχών τα οποία φέρονται να παραιτήθηκαν από μετονομασθέν υπουργείο, σε σχέση με εκείνο που ανέλαβαν. Για τους σκοπούς του dataset, επιλέχθηκε να διατηρηθεί η ονομασία του υπουργείου τη στιγμή που κάποιος ανέλαβε καθήκοντα.
- Περιπτώσεις σφαλμάτων στην καταχώρηση δεδομένων, προερχόμενων από την ίδια ιστοσελίδα, διορθώθηκαν. Για παράδειγμα, στη σελίδα για την τρέχουσα κυβέρνηση, ο Παναγιώτης Μηταράκης φέρεται να παραιτήθηκε από Υφυπουργός Εργασίας και Κοινωνικών Υποθέσεων στις 15 Ιανουαρίου 2020 και, επίσης, να παραιτήθηκε από Υπουργός Μετανάστευσης και Ασύλου την ίδια ημερομηνία, ενώ στην πραγματικότητα διορίστηκε ως τέτοιος (βλ. ΦΕΚ Α’ 5/15-1-2020).
- Επί κυβέρνησης Κωνσταντίνου Μητσοτάκη, οι θέσεις Υπουργών Χωρίς Χαρτοφυλάκιο μετατράπηκαν σε θέσεις Υπουργών Επικρατείας με τον Ν. 1943/1991. Σε αυτήν την περίπτωση, αποδόθηκαν από την ομάδα εργασίας και οι δύο ρόλοι στα αντίστοιχα κυβερνητικά στελέχη, με τις ανάλογες ημερομηνίες έναρξης και λήξης κάθε θητείας. Ως ημερομηνία έναρξης του ρόλου «Υπουργός Επικρατείας», για τα ανάλογα στελέχη, ορίστηκε η ημερομηνία δημοσίευσης του Ν. 1943/1991 (11 Απριλίου 1991).
Αντιστοίχιση ομιλούντων με ομιλίες
Από τα συλλεχθέντα πρακτικά, ήταν δυνατός ο εντοπισμός του ονοματεπώνυμου του ομιλητή, όπως εκείνος ήταν καταγεγραμμένος στο κείμενο, πριν από την έναρξη της ομιλίας του.
Για κάθε ομιλητή x που εντοπίστηκε στα κείμενα των πρακτικών:
- ανατρέξαμε στην ημερομηνία του αρχείου των πρακτικών της συνεδρίασης,
- από το δεύτερο σύνολο δεδομένων με τη δραστηριότητα των κοινοβουλευτικών και κυβερνητικών προσώπων, ανακτήσαμε μόνο τα ονοματεπώνυμα των μελών εκείνων που φαίνεται να είχαν ενεργή δραστηριότητα την ημερομηνία αναφοράς –εστιάζοντας, έτσι, σε ένα υποσύνολο υποψήφιων προσώπων,
- με τη χρήση της βιβλιοθήκης jellyfish και, συγκεκριμένα, της μεθόδου Jaro-Winkler Similarity, συγκρίναμε κάθε ονοματεπώνυμο του εν λόγω υποσυνόλου με το ονοματεπώνυμο του ομιλητή x, που νωρίτερα εξήχθη από τα πρακτικά της συνεδρίασης: στις περιπτώσεις όπου η ομοιότητα μεταξύ δύο ονοματεπώνυμων υπό σύγκριση ήταν υψηλότερη από 95%, αποδώσαμε την ομιλία στο επίσημο πρόσωπο, όπως αυτό εμφανίζεται στο σύνολο των δεδομένων που διατηρούμε για τα μέλη και τη δραστηριότητά τους.
Απόσπασμα του κώδικα για την αντιστοίχιση ονομάτων
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40temp_max = 0 # put these transpositions in the beginning, before we remove '-' # If member has more than one first names if '-' in member_name: # there are cases like member name being δενδιας νικολαος-γεωργιος # and detected speaker being ΝΙΚΟΛΑΟΣ ΔΕΝΔΙΑΣ # if member has two first names if len(member_name.split('-'))==2: member_name1, member_name2 = member_name.split('-') # if member has three first names elif len(member_name.split('-'))==3: member_name1, member_name2, member_name3 = member_name.split('-') # if member has more than one first names and one surname if '-' not in member_surname: # do the following for two first names sim5 = jellyfish.jaro_winkler_similarity(speaker_name, member_name1+' '+member_surname) sim6 = jellyfish.jaro_winkler_similarity(speaker_name, member_surname+' '+member_name1) sim7 = jellyfish.jaro_winkler_similarity(speaker_name, member_name2+' '+member_surname) sim8 = jellyfish.jaro_winkler_similarity(speaker_name, member_surname+' '+member_name2) temp_max = max(temp_max, sim5, sim6, sim7, sim8) # Extra comparisons for alternative names of members temp_max = compare_with_alternative_sim(speaker_name, member_name1, member_surname, temp_max, greek_names) temp_max = compare_with_alternative_sim(speaker_name, member_name2, member_surname, temp_max, greek_names) # do the following extra for three first names # for example κουικ φιλιππου τερενς-σπενσερ-νικολαος if len(member_name.split('-'))==3: sim9 = jellyfish.jaro_winkler_similarity(speaker_name, member_name3+' '+member_surname) sim10 = jellyfish.jaro_winkler_similarity(speaker_name, member_surname+' '+member_name3) temp_max = max(temp_max, sim9, sim10) # Extra comparisons for alternative names of members temp_max = compare_with_alternative_sim(speaker_name, member_name3, member_surname, temp_max, greek_names)
Οι ομιλούντες δεν είναι καταγεγραμμένοι στα πρακτικά πάντα με το ίδιο μοτίβο: για παράδειγμα, το επώνυμο μπορεί να προηγείται ή να έπεται του ονόματος, ή το επίσημο όνομα μπορεί να είχε αντικατασταθεί με ένα υποκοριστικό, ή ο ομιλητής μπορεί να αποκαλείται με το ονοματεπώνυμό του και το υποκοριστικό του, με το οποίο είναι γνωστότερος, να αναφέρεται εντός παρενθέσεως. Τέλος, κάποια πρόσωπα με περισσότερα από ένα ονόματα ή επώνυμα μπορεί να αναφέρονται με ένα από αυτά, κατά περίπτωση. Δεδομένου του ότι η μετρική Jaro-Winkler λαμβάνει υπόψη τη σειρά των γραμμάτων για τη σύγκριση δύο λέξεων, τα ονοματεπώνυμα «Φωτεινή Γεννηματά» και «Γεννηματά Φωτεινή» θα είχαν μηδαμινή ομοιότητα, για παράδειγμα. Ομοίως, τα ονοματεπώνυμα «Φώφη Γεννηματά», «Φωτεινή Γεννηματά», «Φωτεινή-Φώφη Γεννηματά», που αναφέρονται στο ίδιο πρόσωπο, δεν θα μπορούσαν να ταυτιστούν. Για αυτόν τον λόγο, για κάθε σύγκριση ενός εντοπισθέντος ομιλητή με ένα επίσημο ονοματεπώνυμο κοινοβουλευτικού ή κυβερνητικού προσώπου, κατασκευάσαμε όλους τους πιθανούς τρόπους με τους οποίους μπορεί να κληθεί το επίσημο όνομα, εναλλάσσοντας τη σειρά των λέξεων που απαρτίζουν το ονοματεπώνυμο και αντικαθιστώντας ή συνδυάζοντας το όνομα με όλα τα πιθανά υποκοριστικά του. Στη συνέχεια, υπολογίσαμε την ομοιότητα όλων των πιθανών ζευγών και λάβαμε υπόψη την υψηλότερη.
Ελέγχθηκε, αλλά δεν εντοπίστηκε, περίπτωση συνωνυμίας, μέσα στο ίδιο χρονικό διάστημα θητείας, μεταξύ των προσώπων από την επίσημη λίστα κοινοβουλευτικών και κυβερνητικών μελών.
Οι περιπτώσεις ελλειμμάτων στα πρακτικά αντιμετωπίστηκαν ως εξής:
- Εάν ήταν εφικτή η απόδοση της ομιλίας σε ρόλο (για παράδειγμα, «πρόεδρος» ή «μάρτυς»), χωρίς να είναι δυνατή η αντιστοίχισή της με ονοματεπώνυμο, τότε η ομιλία διατηρήθηκε στο dataset –με κενή τιμή στον ομιλούντα.
- Όταν δεν στάθηκε δυνατή η αντιστοίχιση της ομιλίας με κάποιο συγκεκριμένο πρόσωπο ή, έστω, με συγκεκριμένο ρόλο, τότε η ομιλία διεγράφη και δεν περιλαμβάνεται στο dataset. Τέτοιες περιπτώσεις προέκυψαν λόγω ασυνεπούς/μη συστηματοποιημένης μορφοποίησης σε αποσπάσματα ορισμένων πρακτικών.
1 Το dataset δημιουργήθηκε για λογαριασμό του iMEdD, στo πλαίσιo του πυλώνα Lab, από την Κωνσταντίνα Δρίτσα (producer), σε συνεργασία με τη δημοσιογράφο και Project Manager του iMEdD Lab Κέλλυ Κική. Η μεθοδολογία εργασίας για τη συλλογή των πρακτικών των συνεδριάσεων της Ολομέλειας της Βουλής των Ελλήνων και την επεξεργασία των δεδομένων βασίζεται σε προγενέστερη τεχνογνωσία, η οποία είχε αναπτυχθεί στο πλαίσιο διπλωματικής μεταπτυχιακής εργασίας της Κωνσταντίνας Δρίτσα, με επιβλέποντα τον Πάνο Λουρίδα, Αναπληρωτή Καθηγητή στο Τμήμα Διοικητικής Επιστήμης και Τεχνολογίας στο Οικονομικό Πανεπιστήμιο Αθηνών.
Γραφιστική Επιμέλεια: Ευγένιος Καλοφωλιάς