


Ένας οδηγός του Pulitzer Center για το πώς η τεχνητή νοημοσύνη διευκολύνει τους δημοσιογράφους να αντλήσουν δεδομένα από αδιαφανείς κυβερνητικές ιστοσελίδες.
Ο παρών οδηγός δημοσιεύθηκε αρχικά από το Pulitzer Center στις 13/10/2025 και αναδημοσιεύεται στα ελληνικά από το iMEdD με την άδειά του. Οποιαδήποτε άδεια αναδημοσίευσης υπόκειται στον αρχικό εκδότη. Διαβάστε τον αρχικό οδηγό εδώ.
Εικονογράφηση: Ευγένιος Καλοφωλιάς
Μετάφραση: Ανατολή Σταυρουλοπουλου
- Πότε αξίζει να φτιάξετε έναν web scraper;
- 1. Κατανοήστε πώς είναι φτιαγμένη η ιστοσελίδα (στατική ή δυναμική)
- 2. Φτιάξτε τον scraper σας με LLMs (για στατική σελίδα)
- 3. Επιπλέον βήματα για δυναμικές ιστοσελίδες
- 4. Δημιουργία πολλών scrapers για μια βάση δεδομένων με πολλαπλά επίπεδα
- 5. Συχνές στρατηγικές παράκαμψης του μπλοκαρίσματος
- 6. Προχωρημένο scraping: Προγραμματισμός του scraper
Unpacking the story: Το κρυφό εμπόριο κρέατος καρχαρία στη Βραζιλία

Οι δημοσιογράφοι του Mongabay Κάρλα Μέντες και Φίλιπ Τζέικομπσον αποκαλύπτουν πως τοξικό κρέας καρχαρία σερβίρεται κρυφά σε σχολεία, νοσοκομεία και φυλακές.
Τα δεδομένα είναι βασικό κομμάτι της ερευνητικής δημοσιογραφίας. Βοηθούν τους δημοσιογράφους να επιβεβαιώνουν θεωρίες, να αποκαλύπτουν κρυμμένες πληροφορίες, να ακολουθούν τις διαδρομές του χρήματος, να επεκτείνουν το εύρος μιας έρευνας και να ενισχύουν την αξιοπιστία ενός ρεπορτάζ. Η ομάδα Data and Research του Pulitzer Center έχει στηρίξει μεγάλες έρευνες που αφορούν, μεταξύ άλλων, τις προμήθειες κρέατος καρχαρία από την κυβέρνηση της Βραζιλίας, επενδυτικά εργαλεία, μέσω των οποίων χρηματοδοτούνται παραβιάσεις περιβαλλοντικών κανόνων στον Αμαζόνιο και τον αδιαφανή αλγόριθμο («μαύρο κουτί») μιας δημοφιλούς εφαρμογής ταξί στη Νοτιοανατολική Ασία.
Πριν να ξεκινήσουμε μια έρευνα βασισμένη σε δεδομένα, συνήθως θέτουμε τρία ερωτήματα για να δούμε κατά πόσο αυτή είναι εφικτή:
- Είναι τα δεδομένα δημόσια διαθέσιμα;
- Πόσο καλή είναι η ποιότητά τους;
- Πόσο δύσκολη είναι η πρόσβαση σε αυτά;
Ακόμη κι αν οι δύο πρώτες απαντήσεις είναι ξεκάθαρα «ναι», η υπόθεση δεν έκλεισε. Συχνά, το τρίτο ερώτημα είναι το πιο απαιτητικό και χρονοβόρο στάδιο ολόκληρης της διαδικασίας.
Πότε αξίζει να φτιάξετε έναν web scraper;
Η πρόσβαση σε δεδομένα, που δημοσιεύονται στο διαδίκτυο, μπορεί να είναι μια απλή υπόθεση μερικών κλικ για να αντιγράψουμε πίνακες ή να κατεβάσουμε ένα αρχείο δεδομένων. Συχνά, όμως, χρειάζεται να εξάγουμε μεγάλα σύνολα δεδομένων από βάσεις ή ιστοσελίδες και να τα μεταφέρουμε σε άλλη πλατφόρμα για ανάλυση. Εάν η ιστοσελίδα δεν προσφέρει δυνατότητα λήψης (download), πρώτα επικοινωνούμε με τους υπεύθυνους για να ζητήσουμε πρόσβαση. Σε ορισμένες χώρες, εάν τα δεδομένα ανήκουν σε δημόσιες Aρχές, μπορεί να ζητηθεί πρόσβαση, μέσω αιτήματος Ελευθερίας Πληροφόρησης (Freedom of Information – FOI) ή Δικαιώματος στην Πληροφόρηση (Right to Information – RTI). Ωστόσο, αυτή η διαδικασία έχει συνήθως τις δικές της δυσκολίες, που δεν θα αναλύσουμε εδώ.
Eάν δεν είναι διαθέσιμες οι παραπάνω επιλογές, ίσως χρειαστεί να εξάγουμε τα δεδομένα χειροκίνητα από την ιστοσελίδα. Για να γίνει αυτό, πολλές φορές χρειάζεται να κάνουμε συνεχόμενα κλικ στο «επόμενη σελίδα», να επαναλάβουμε εκατοντάδες φορές τη διαδικασία «αντιγραφής-επικόλλησης», να ανοίξουμε εκατοντάδες URLs, για να κατεβάσουμε αρχεία ή να κάνουμε πολλαπλές αναζητήσεις με διαφορετικές παραμέτρους, σώζοντας παράλληλα όλα τα αποτελέσματα. Ενδέχεται να χρειαστούν εκατοντάδες χιλιάδες επαναλήψεις, ανάλογα με τον όγκο των δεδομένων και τον σχεδιασμό της ιστοσελίδας. Όταν διαθέτουμε τον χρόνο και τα χρήματα, αυτό είναι εφικτό, ωστόσο για πολλούς δημοσιογράφους και Μέσα, αυτά είναι πολυτέλεια.
Εδώ μπαίνει στο παιχνίδι το web scraping, η τεχνική που χρησιμοποιεί ένα πρόγραμμα για να αυτοματοποιήσει την εξαγωγή συγκεκριμένων δεδομένων από online πηγές και να τα οργανώσει σε μορφή που επιλέγει ο χρήστης (π.χ. ένα υπολογιστικό φύλλο ή αρχείο CSV). Το εργαλείο που το κάνει αυτό ονομάζεται scraper.
Σημείωση: Το νομικό και ηθικό πλαίσιο του web scraping ξεφεύγει από το αντικείμενο αυτής της ανάλυσης. Εάν έχετε αμφιβολίες για το κατά πόσο η εξαγωγή δεδομένων από μια συγκεκριμένη ιστοσελίδα στη χώρα σας είναι νόμιμη, ζητήστε νομικές συμβουλές.
Υπάρχουν πολλά έτοιμα εργαλεία scraping που δεν απαιτούν προγραμματισμό. Σε αυτά συμπεριλαμβάνονται διάφορα extensions (επεκτάσεις) για τον Chrome, όπως τα Instant Data Scraper, Table Capture, Scraper, Web Scraper, και Data Miner. Τα περισσότερα απαιτούν συνδρομή, αν και κάποια προσφέρουν δωρεάν πρόσβαση σε μη κερδοσκοπικούς φορείς, δημοσιογράφους και ερευνητές (π.χ. Oxylabs).
Τα περισσότερα εμπορικά εργαλεία scraping έχουν σχεδιαστεί για δημοφιλείς ιστοσελίδες ηλεκτρονικών καταστημάτων, μέσων κοινωνικής δικτύωσης, αποτελεσμάτων αναζήτησης, πλατφόρμες κρατήσεων ξενοδοχείων και ειδησεογραφικές ιστοσελίδες. Ωστόσο, μια ιστοσελίδα μπορεί να κατασκευαστεί με πολλούς διαφορετικούς τρόπους και οι δημοσιογράφοι συχνά έρχονται αντιμέτωποι με δύσχρηστες και «αφιλόξενες» κυβερνητικές βάσεις δεδομένων. Όταν τα εμπορικά εργαλεία δεν ανταποκρίνονται στις απαιτήσεις αυτών των δεδομένων, φτιάχνουμε προσαρμοσμένα (custom) scrapers. Η δημιουργία δικού μας εργαλείου ενδέχεται να είναι φθηνότερη και ταχύτερη, αφού δεν χρειαζόμαστε τις επιπλέον δυνατότητες που προσφέρουν οι εμπορικά scrapers.
Η κατασκευή scrapers παλαιότερα απαιτούσε εξειδικευμένες γνώσεις προγραμματισμού. Στις πρόσφατες έρευνές μας, όμως, τα μεγάλα γλωσσικά μοντέλα (LLMs) όπως το ChatGPT, το Google Gemini ή το Claude, μας βοήθησαν να φτιάξουμε scrapers για πολύπλοκες βάσεις δεδομένων πολύ πιο γρήγορα και χωρίς προηγμένες γνώσεις προγραμματισμού. Με βασικές γνώσεις διαδικτύου, καθοδήγηση και παραδείγματα, ακόμη και δημοσιογράφοι χωρίς τεχνικές γνώσεις μπορούν να φτιάξουν ένα scraper χρησιμοποιώντας LLMs. Ακολουθεί η δική μας «συνταγή»:
1. Κατανοήστε πώς είναι φτιαγμένη η ιστοσελίδα (στατική ή δυναμική)
Πριν να ζητήσετε από ένα μεγάλο γλωσσικό μοντέλο (LLM) να γράψει ένα script (μια δέσμη ενεργειών), πρέπει να έχετε μια γενική εικόνα για το πώς είναι φτιαγμένη η ιστοσελίδα που σας ενδιαφέρει, ειδικά όσον αφορά τον τρόπο με τον οποίο φορτώνονται τα δεδομένα, που θέλετε να εξάγετε. Ένας βασικός διαχωρισμός που πρέπει να γνωρίζετε είναι μεταξύ μιας στατικής και μιας δυναμικής ιστοσελίδας.
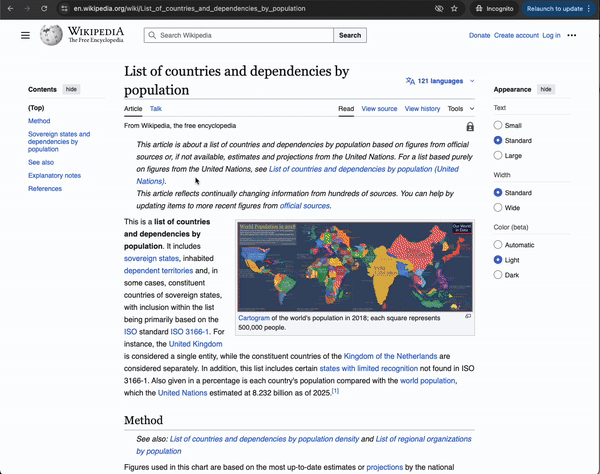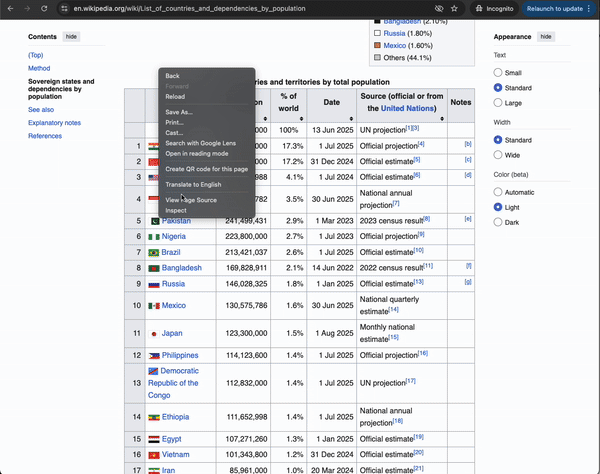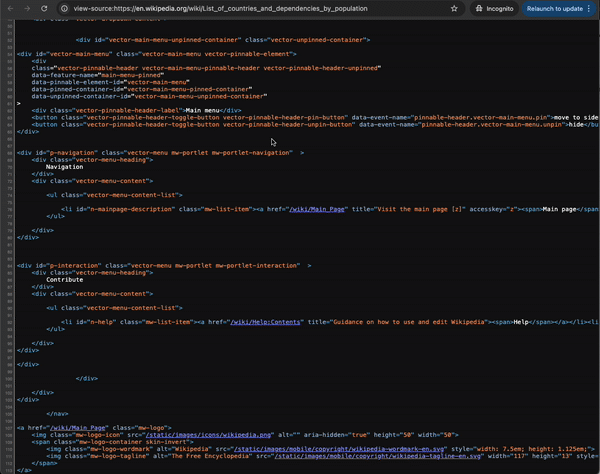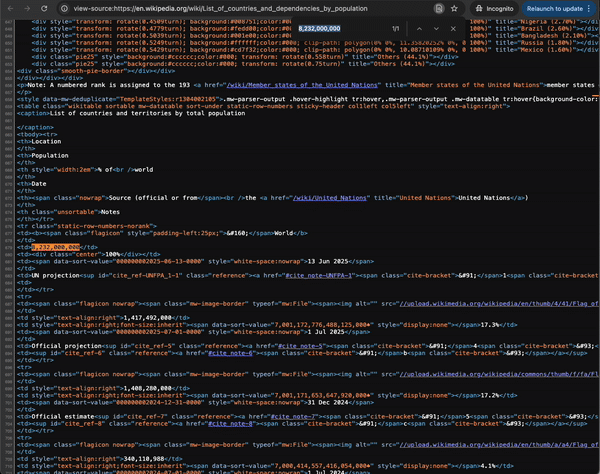
Μια στατική (static) σελίδα είναι σαν μια έντυπη εφημερίδα. Το περιεχόμενο δεν αλλάζει μετά τη δημιουργία του, εκτός αν κάποιος επεξεργαστεί την ιστοσελίδα. Αυτό που βλέπετε είναι ακριβώς αυτό που υπάρχει στον server. Εάν κάνετε ανανέωση, θα δείτε πάλι το ίδιο περιεχόμενο. Ένα τέτοιο παράδειγμα είναι μια σελίδα της Wikipedia με λίστα κρατών.
Μια δυναμική (dynamic) σελίδα μοιάζει με το feed στα μέσα κοινωνικής δικτύωσης, όπου το περιεχόμενο αλλάζει αυτόματα ανάλογα με το ποιος το επισκέπτεται, τι κλικάρει ή ποια νέα δεδομένα είναι διαθέσιμα. Όταν φορτώνετε ή ανανεώνετε τη σελίδα, ο browser εκτελεί συνήθως scripts και επικοινωνεί με μια βάση δεδομένων ή ένα API (μια διεπαφή προγραμματισμού εφαρμογών) για να βρει το περιεχόμενο. Ένα παράδειγμα δυναμικής ιστοσελίδας που χρησιμοποιήσαμε για τη δημοσιογραφική έρευνα σχετικά με τις προμήθειες κρέατος καρχαρία ήταν η βάση δεδομένων δημόσιων προμηθειών του Σάο Πάολο, η οποία απαιτείται συμπλήρωση του πεδίου αναζήτησης για την εμφάνιση των δεδομένων.
Οι στατικές σελίδες είναι συνήθως πιο εύκολες στην εξαγωγή δεδομένων, γιατί αυτά υπάρχουν ήδη στον κώδικα HTML της σελίδας, ενώ οι δυναμικές συχνά απαιτούν επιπλέον βήματα, καθώς τα δεδομένα είναι κρυμμένα πίσω από scripts ή φορτώνονται μόνο μετά από αλληλεπίδραση με τη σελίδα. Σε αυτήν την περίπτωση απαιτείται πιο προηγμένος scraper, αλλά μην ανησυχείτε, θα σας δείξουμε πώς να το φτιάξετε.
Κάποιες φορές, βέβαια, δεν φαίνεται αν μια ιστοσελίδα είναι δυναμική ή στατική μόνο με μια ματιά. Κάποιες σελίδες που μοιάζουν στατικές είναι στην πραγματικότητα δυναμικές. Κάντε ένα γρήγορο τεστ: Ανοίξτε τη σελίδα, κάντε δεξί κλικ και επιλέξτε «Προβολή Πηγής Σελίδας» (στο Chrome) για να δείτε τον κώδικα HTML. Χρησιμοποιήστε το Find (Ctrl+F / Cmd+F) για να ψάξετε τα δεδομένα που θέλετε να εξάγετε. Εάν τα δεδομένα υπάρχουν μέσα στον κώδικα, η σελίδα είναι πιθανότατα στατική. Εάν όχι, η σελίδα είναι μάλλον δυναμική.
Εναλλακτικά, μπορείτε να ζητήσετε από ένα LLM να το ελέγξει. Προτεινόμενη εντολή (prompt):
Αυτό είναι το URL μιας ιστοσελίδας [παραθέστε παρακάτω] από την οποία θέλω να εξάγω δεδομένα. Μπορείς να μου πεις αν οι πληροφορίες και τα δεδομένα στη σελίδα είναι άμεσα διαθέσιμα στον κώδικα [στατικά] ή αν φορτώνονται αργότερα με scripts [δυναμικά];
Για μεγάλα γλωσσικά μοντέλα χωρίς δυνατότητα περιήγησης στο διαδίκτυο, αντιγράψτε και επικολλήστε ολόκληρο τον πηγαίο κώδικα HTML της σελίδας και αντικαταστήστε το «URL» στην εντολή, γράφοντας «HTML της σελίδας». Εάν ο πηγαίος κώδικας ξεπερνά το ανώτατο όριο που δέχεται η εντολή, θα χρειαστεί να επιλέξετε το τμήμα που περιέχει τα δεδομένα που σας ενδιαφέρουν. Το Βήμα 3 θα εξηγήσει πώς να το κάνετε.
Για να γίνει πιο κατανοητό, ακολουθεί ένα παράδειγμα από μια πραγματική έρευνά μας. Ζητήσαμε από το ChatGPT (μοντέλο GPT-5) να εξετάσει τη σελίδα με τα δελτία Τύπου της εταιρείας The Metals Company. Εξήγαμε όλες τις ανακοινώσεις για να αναλύσουμε τα δημόσια μηνύματα της εταιρείας σχετικά με τις εξορύξεις βαθέων υδάτων. Το ChatGPT εντόπισε ότι η σελίδα ήταν στατική.

2. Φτιάξτε τον scraper σας με LLMs (για στατική σελίδα)
Εάν η σελίδα είναι στατική, μπορείτε να ζητήσετε από ένα μεγάλο γλωσσικό μοντέλο (LLM) να γράψει ένα Python script για scraping (η Python είναι η πιο κοινή γλώσσα προγραμματισμού για scraping). Στην εντολή σας προς το LLM, περιλάβετε τα εξής:
- Τη διεύθυνση (URL) της ιστοσελίδας
- Τον πηγαίο κώδικα HTML της ιστοσελίδας (προαιρετικό, αλλά ενισχύει την αξιοπιστία)
- Ποια δεδομένα χρειάζεστε να εξάγετε (πεδία/στήλες)
- Πού και πώς θα αποθηκεύσετε τα δεδομένα (π.χ. σε αρχείο CSV)
- Πληροφορίες για την «αρχιτεκτονική» των σελίδων (Έχει πολλαπλές σελίδες η ιστοσελίδα; Πώς θα κάνετε πλοήγηση σε όλες;)
- Πού θα «τρέξετε» το scraper (στον υπολογιστή σας ή σε online πλατφόρμα, π.χ. Google Colab)
- Τελικός έλεγχος: Ρωτήστε αν το LLM χρειάζεται κάποια άλλη πληροφορία πριν δημιουργήσει το script
Παράδειγμα εντολής που δώσαμε στο ChatGPT:
[Σημείωση της επιμέλειας: Παραθέτουμε αυτούσιες τις πρωτογενείς εντολές (prompts). Ακολουθεί απόδοση στα ελληνικά, προς διευκόλυνση η οποία όμως πρέπει να αξιολογηθεί από τους χρήστες.]
I need to build a scraper for the web page below. It is a static web page. Write me a Python script to scrape the webpage from my computer. https://investors.metals.co/news-events/press-releases
It has a list of press releases with title, date, and URL to the press release page. I need all 3 of them stored in separate columns in a CSV file. The web page has pagination. I need the full list of press releases from all pages. Here’s the HTML source code: [paste the full HTML source code]
Χρειάζομαι ένα scraper για την παρακάτω σελίδα. Είναι στατική σελίδα. Γράψε ένα Python script για να εξάγω τα δεδομένα από τον υπολογιστή μου: https://investors.metals.co/news-events/press-releases
Η σελίδα περιέχει λίστα με δελτία Τύπου που έχουν τίτλο, ημερομηνία και διεύθυνση (URL) των δελτίων Τύπου. Χρειάζομαι και τα τρία αυτά στοιχεία αποθηκευμένα σε ξεχωριστές στήλες σε ένα αρχείο CSV. Η ιστοσελίδα έχει σελίδωση (pagination). Θέλω ολόκληρη τη λίστα με όλα τα δελτία από όλες τις σελίδες. Αυτός είναι ο πηγαίος κώδικας HTML: [επικολλήστε ολόκληρο το HTML]
Τα δελτία Τύπου βρίσκονται σε πολλές διευθύνσεις, προσβάσιμες μέσω της γραμμής πλοήγησης στο κάτω μέρος της σελίδας. Παρόλο που δώσαμε μόνο το URL της πρώτης σελίδας στο ChatGPT, αυτό μπόρεσε να προβλέψει και τα υπόλοιπα, προσθέτοντας “?page=N” στη βάση του URL.
Το ChatGPT θα γράψει ένα script μαζί με σύντομη εξήγηση. Αντιγράψτε το σε έναν κειμενογράφο (εμείς χρησιμοποιούμε το Visual Studio Code), αποθηκεύστε το ως αρχείο Python (.py) και τρέξτε το στο Terminal (macOS) ή στο PowerShell (Windows).
Eάν δεν έχετε ξανατρέξει Python script στον υπολογιστή σας, θα χρειαστεί μια γρήγορη εγκατάσταση. Τα μεγάλα γλωσσικά μοντέλα μπορούν να δημιουργήσουν οδηγίες βήμα προς βήμα, χρησιμοποιώντας την παρακάτω εντολή. Συνήθως απαιτείται εγκατάσταση της Python (και του διαχειριστή πακέτων της, Pip, ή του Homebrew στο macOS), καθώς και των βασικών βιβλιοθηκών για scraping, όπως τα Requests, Beautifulsoup4 και προαιρετικά το Selenium.
I need to run a Python scraping script on macOS/Windows. Show me step-by-step setup instructions.
Θέλω να τρέξω ένα Python scraping script σε macOS/Windows. Δείξε μου βήμα-βήμα τις οδηγίες εγκατάστασης.
Συμβουλή: Γράψτε τις εντολές σε μία συνομιλία με το LLM, ώστε να διατηρηθεί το πλαίσιο. Εάν το script δεν δουλέψει ή εμφανιστούν σφάλματα κατά την εγκατάσταση, αντιγράψτε όλα τα μηνύματα σφάλματος ή τα logs και ζητήστε από το μοντέλο να τα διορθώσει. Μπορεί να χρειαστούν μερικές επαναλήψεις μέχρι να λειτουργήσουν όλα.
3. Επιπλέον βήματα για δυναμικές ιστοσελίδες
Η εξαγωγή δεδομένων από μια δυναμική ιστοσελίδα απαιτεί λίγα παραπάνω βήματα, καθώς και κάποιες βασικές γνώσεις ανάπτυξης ιστοσελίδων, ωστόσο τα LLM μπορούν και εδώ να κάνουν τη δύσκολη δουλειά.
Εάν η σελίδα χρειάζεται να αλληλεπιδράσετε μαζί της για να εμφανίσει τα δεδομένα, πρέπει να εξηγήσετε στο LLM ποιες ακριβώς ενέργειες χρειάζεται να εκτελέσει και πού βρίσκονται τα δεδομένα που θέλετε να συλλέξετε. Σε αντίθεση με μια στατική σελίδα, αυτές οι πληροφορίες δεν υπάρχουν έτοιμες στον απλό κώδικα HTML. Το μοντέλο θα σας δείξει πώς να εγκαταστήσετε βιβλιοθήκες Python όπως η Selenium και η Playwright, οι οποίες ανοίγουν τον φυλλομετρητή (browser) είτε κανονικά είτε σε λειτουργία χωρίς παράθυρο και αλληλεπιδρούν με μια ιστοσελίδα όπως θα έκανε ένας άνθρωπος.
Ας χρησιμοποιήσουμε το παράδειγμα της βάσης δεδομένων δημοσίων προμηθειών στο Σάο Πάολο. Εκεί πρέπει να συμπληρώσεις ή να επιλέξεις ορισμένα από τα 12 πεδία της φόρμας και να πατήσεις το κουμπί Buscar (αναζήτηση), για να εμφανιστεί ο πίνακας.
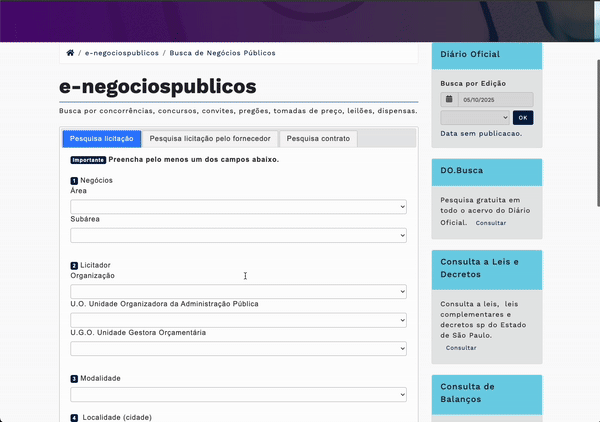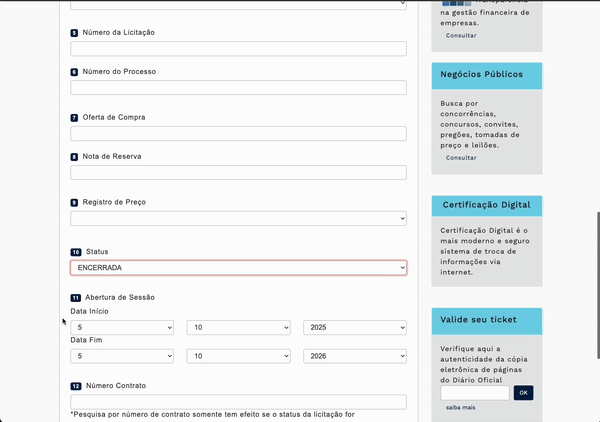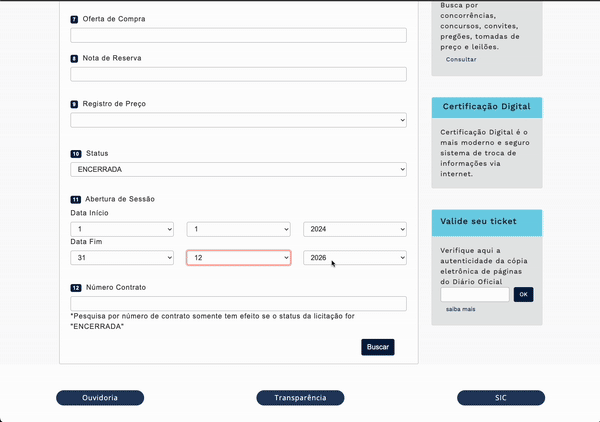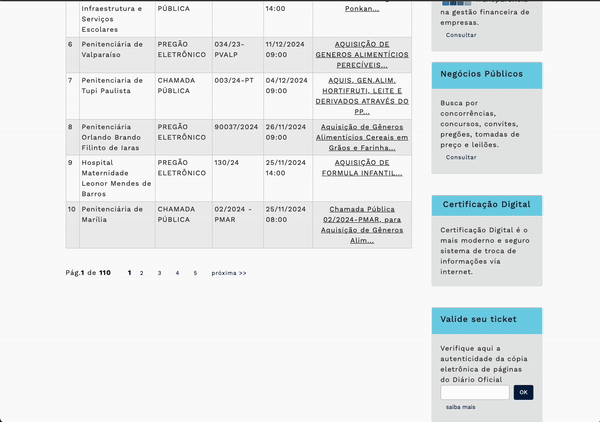
Σε αυτήν την περίπτωση, ο scraper λειτουργεί σαν ρομπότ. Μιμείται τις κινήσεις σας, περιμένει να φορτώσουν τα δεδομένα και μετά τα συλλέγει. Για να του πείτε ποια πεδία να συμπληρώσει, ποιες επιλογές να διαλέξει, ποια κουμπιά να πατήσει και ποιους πίνακες ή λίστες να εξαγάγει, θα χρειαστούν τα «ονόματα» των στοιχείων της σελίδας. Εκεί βοηθούν οι βασικές γνώσεις HTML.
Η HTML είναι η γλώσσα με την οποία δομείται μια ιστοσελίδα. Κάθε πληροφορία στη σελίδα «κατοικεί» μέσα σε ένα στοιχείο HTML. Είναι κάτι σαν κουτάκια που φιλοξενούν κείμενο ή δεδομένα. Συνηθισμένα στοιχεία είναι τα <h1> για τίτλους, <a> για συνδέσμους, <table> για πίνακες δεδομένων και <p> για παραγράφους. Πολλά στοιχεία έχουν επίσης χαρακτηριστικά (τις «ετικέτες» τους), όπως το class και το id, που τα ξεχωρίζουν.
Πρέπει, λοιπόν, να γνωρίζουμε ποια στοιχεία είναι αυτά με τα οποία πρέπει να αλληλεπιδράσουμε, ποια είναι αυτά που περιέχουν τα δεδομένα που θέλουμε και ποια είναι τα χαρακτηριστικά τους (class ή id), ώστε να δώσουμε στο LLM ακριβείς οδηγίες.
Για παράδειγμα, παρακάτω βλέπετε το HTML στοιχείο του πρώτου πεδίου, Área, στο πεδίο αναζήτησης (search box) της βάσης του Σάο Πάολο. Πρόκειται για ένα στοιχείο <select> με id “content_content_content_Negocio_cboArea” και class “form-control”. Μπορείτε να το αντιγράψετε και να το επικολλήσετε στο prompt σας, ώστε το γλωσσικό μοντέλο να χτίσει σωστά το scraper:
<select name="ctl00$ctl00$ctl00$content$content$content$Negocio$cboArea"
id="content_content_content_Negocio_cboArea"
class="form-control"
onchange="javascript:CarregaSubareasNegocios();">
<option value=""></option>
<option value="8">Atividade</option>
<option value="6">Imóveis</option>
<option value="3">Materiais e Equipamentos</option>
<option value="2">Obras</option>
<option value="7">Projeto</option>
<option value="4">Recursos Humanos</option>
<option value="1">Serviços Comuns</option>
<option value="5">Serviços de Engenharia</option>
</select>
Ένα στοιχείο HTML μπορεί να βρίσκεται μέσα σε κάποιο άλλο στοιχείο, σχηματίζοντας στρώματα ιεραρχικής δομής. Για παράδειγμα, ένας πίνακας <table> συνήθως περιέχει πολλές σειρές <tr> και κάθε σειρά περιέχει πολλά κελιά <td>. Σε ορισμένες περιπτώσεις, ίσως χρειαστεί να το εξηγήσετε αυτό στο LLM, για να μειώσετε τα λάθη.
Για να εντοπίσετε ένα στοιχείο και τα χαρακτηριστικά του, κάντε δεξί κλικ πάνω του και επιλέξτε Επιθεώρηση/Inspect (στο Chrome). Αυτό ανοίγει τα Εργαλεία για Προγραμματιστές/DevTools, όπου εμφανίζεται ο κώδικας HTML της σελίδας και τα χαρακτηριστικά του στοιχείου. Το επιλεγμένο στοιχείο επισημαίνεται. Όταν περάσετε τον δείκτη πάνω από το στοιχείο στα DevTools, επισημαίνεται το αντίστοιχο περιεχόμενο στη σελίδα. Για να το αντιγράψετε, κάντε δεξί κλικ στο στοιχείο στον πίνακα Στοιχεία/Elements και επιλέξτε Αντιγραφή → Αντιγραφή στοιχείου/Copy → Copy element (αντιγράφει ολόκληρο το HTML, συμπεριλαμβανομένων των εσωτερικών στοιχείων). Για να το εντοπίσετε στον κώδικα, επιλέξτε Αντιγραφή → Αντιγραφή selector/Copy → Copy selector (ή Αντιγραφή XPath/Copy XPath), ώστε να πάρετε έναν μοναδικό selector που βοηθά στον εντοπισμό του στοιχείου.
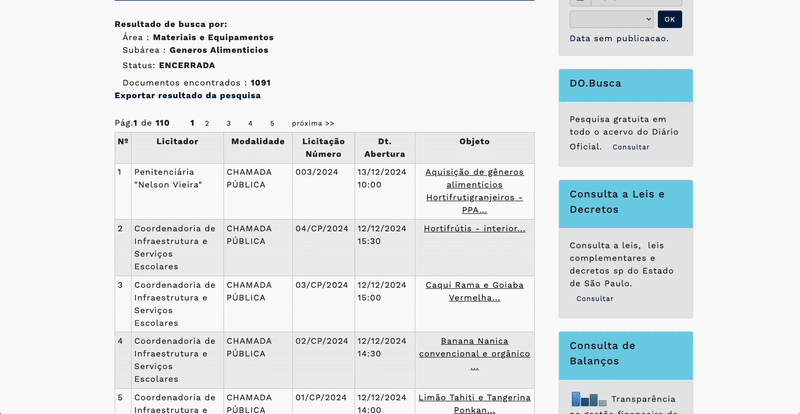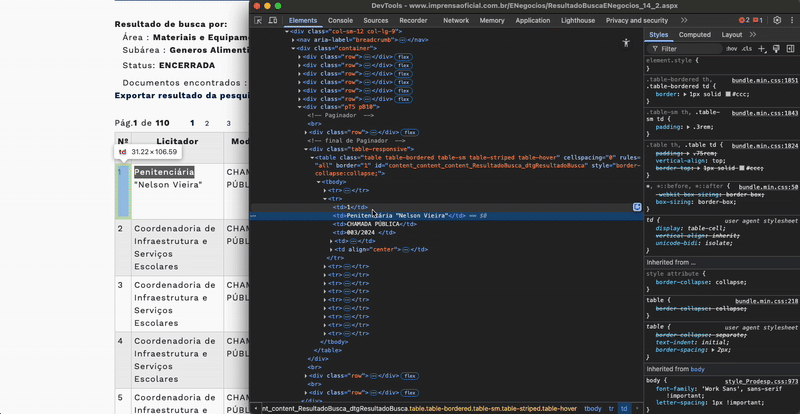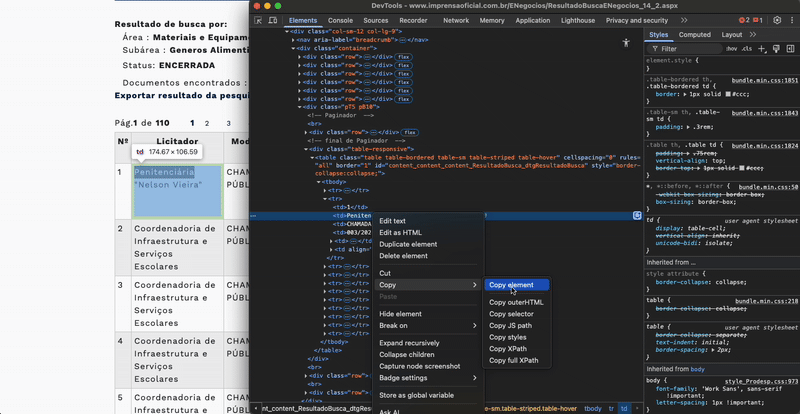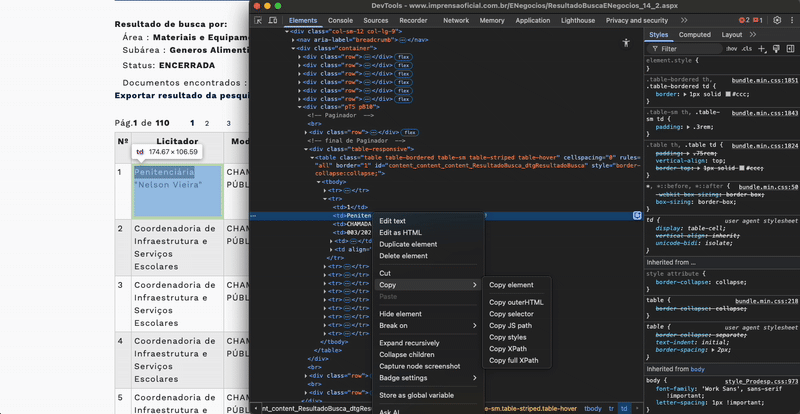
Εάν η σελίδα φορτώνει αργά, πρέπει να πείτε στο LLM να περιμένει λίγο μετά από κάθε ενέργεια.
Για να φτιάξουμε τον scraper για τη βάση δημοσίων προμηθειών του Σάο Πάολο, παρακάτω είναι η εντολή που δώσαμε στο ChatGPT (μοντέλο GPT-5). Θέλουμε να αναζητήσουμε κλειστούς διαγωνισμούς («ENCERRADA») στις κατηγορίες «Materiais e Equipamentos» και «Generos Alimenticios» μεταξύ 1 Ιανουαρίου 2024 και 31 Δεκεμβρίου 2024 (βλέπε το προηγούμενο βίντεο).
I would like to write a Python script that I will run from my computer to scrape data from an online database and store it in a CSV file. It is a dynamic web page. Below are the steps required to view the data. I’ve specified the HTML elements that the scraper should interact with. Print messages at different steps to show progress and help debug any errors. Let me know if you need any more information from me.
Θέλω να φτιάξω ένα Python script που θα τρέχει από τον υπολογιστή μας, ώστε να συλλέξει δεδομένα από μια διαδικτυακή βάση και να τα αποθηκεύσει σε αρχείο CSV. Η σελίδα είναι δυναμική. Παρακάτω φαίνονται τα βήματα που χρειάζεται να ακολουθήσουμε για να εμφανιστούν τα δεδομένα. Έχω προσδιορίσει τα HTML στοιχεία με τα οποία πρέπει να αλληλεπιδράσει ο scraper. Σε κάθε βήμα, φρόντισε να εμφανίζεις μηνύματα για να δείχνεις την πρόοδο και να βοηθάς στον εντοπισμό τυχόν σφαλμάτων. Ενημέρωσέ με αν χρειάζεσαι περαιτέρω πληροφορίες.
1. Πήγαινε στη σελίδα αναζήτησης:
2. Συμπλήρωσε τα κριτήρια αναζήτησης στα εννέα πλαίσια επιλογής (dropdown menus):
<select name="ctl00$ctl00$ctl00$content$content$content$Negocio$cboArea" id="content_content_content_Negocio_cboArea" class="form-control" onchange="javascript:CarregaSubareasNegocios();">Επίλεξε «Generos Alimenticios» για:
<select name="ctl00$ctl00$ctl00$content$content$content$Negocio$cboSubArea" id="content_content_content_Negocio_cboSubArea" class="form-control">Επίλεξε «ENCERRADA» για:
<select name="ctl00$ctl00$ctl00$content$content$content$Status$cboStatus" id="content_content_content_Status_cboStatus" class="form-control" onchange="fncAjustaCampos();">Επίλεξε «1» για:
<select name="ctl00$ctl00$ctl00$content$content$content$Status$cboAberturaSecaoInicioDia" id="content_content_content_Status_cboAberturaSecaoInicioDia" class="form-control">Επίλεξε «1» για:
<select name="ctl00$ctl00$ctl00$content$content$content$Status$cboAberturaSecaoInicioMes" id="content_content_content_Status_cboAberturaSecaoInicioMes" class="form-control">Επίλεξε «2024» για:
<select name="ctl00$ctl00$ctl00$content$content$content$Status$cboAberturaSecaoInicioAno" id="content_content_content_Status_cboAberturaSecaoInicioAno" class="form-control">Επίλεξε «31» για:
<select name="ctl00$ctl00$ctl00$content$content$content$Status$cboAberturaSecaoFimDia" id="content_content_content_Status_cboAberturaSecaoFimDia" class="form-control">Επίλεξε «12» για:
<select name="ctl00$ctl00$ctl00$content$content$content$Status$cboAberturaSecaoFimMes" id="content_content_content_Status_cboAberturaSecaoFimMes" class="form-control">Επίλεξε «2024» για:
<select name="ctl00$ctl00$ctl00$content$content$content$Status$cboAberturaSecaoFimAno" id="content_content_content_Status_cboAberturaSecaoFimAno" class="form-control">3. Χρησιμοποίησε Javascript για να κάνεις κλικ στο κουμπί:
<input type="submit" name="ctl00$ctl00$ctl00$content$content$content$btnBuscar" value="Buscar" onclick="return verify();" id="content_content_content_btnBuscar" class="btn btn-primary">4. Περίμενε να φορτώσει η σελίδα με τα αποτελέσματα και τον πίνακα:
<table class="table table-bordered table-sm table-striped table-hover" cellspacing="0" rules="all" border="1" id="content_content_content_ResultadoBusca_dtgResultadoBusca" style="border-collapse:collapse;"></table>5. Άντλησε όλο το περιεχόμενο του πίνακα. Η πρώτη σειρά <tr> είναι η κεφαλίδα. Υπάρχουν άλλες 10 σειρές <tr> μετά την κεφαλίδα, η κάθε μία με 6 κελιά <td>. Στο αρχείο CSV δημιούργησε μια επιπλέον στήλη (όγδοη), για να αποθηκεύσεις τον σύνδεσμο <href> του τελευταίου <td> (7ο <td>).
6. Πήγαινε στην επόμενη σελίδα των αποτελεσμάτων και επανάλαβε τη διαδικασία μέχρι την τελευταία σελίδα. Ο αριθμός σελίδων εμφανίζεται στο:
<span id="content_content_content_ResultadoBusca_PaginadorCima_QuantidadedePaginas">5659</span>Χρησιμοποίησε Javascript, για να κάνεις κλικ στο κουμπί για την επόμενη σελίδα:
<a id="content_content_content_ResultadoBusca_PaginadorCima_btnProxima" class="btn btn-link xx-small" href="javascript:__doPostBack('ctl00$ctl00$ctl00$content$content$content$ResultadoBusca$PaginadorCima$btnProxima','')">próxima >></a>Μην ξεχνάς να περιμένεις κάθε φορά να φορτώσει πλήρως ο πίνακας πριν να εξάγεις τα δεδομένα.
7. Τα δεδομένα από όλες τις σελίδες πρέπει να προστεθούν στο ίδιο αρχείο CSV.
Πρέπει να σημειώσουμε κάποια πράγματα για το prompt. Ζητήσαμε ρητά από τον scraper να εμφανίζει μηνύματα κατά τη διάρκεια της εκτέλεσης. Αυτό είναι χρήσιμο για την αντιμετώπιση τυχόν σφαλμάτων. Επίσης, δώσαμε εντολή στον scraper να κάνει κλικ στο κουμπί χρησιμοποιώντας JavaScript, που μιμείται το κλικ ενός ανθρώπου. Εάν δεν το προσδιορίσουμε αυτό, το κουμπί μπορεί να ενεργοποιηθεί με άλλους τρόπους που δεν δουλεύουν σε ορισμένες σελίδες. Οι οδηγίες μας ήταν πολύ συγκεκριμένες όσον αφορά το περιεχόμενο του πίνακα, αλλά δεν είναι πάντα απαραίτητο να δίνουμε τόσες λεπτομέρειες, γιατί συνήθως τα LLM μπορούν να τις κατανοήσουν αυτόματα.
Η εξαγωγή δεδομένων από δυναμικές σελίδες συνήθως απαιτεί επιπλέον βιβλιοθήκες Python. Εάν εμφανιστεί μήνυμα σφάλματος που γράφει ModuleNotFoundError, κάνουμε αντιγραφή-επικόλληση στο LLM, το οποίο θα δώσει την εντολή εγκατάστασης. Οι βιβλιοθήκες λειτουργούν σαν εργαλειοθήκες που χρειάζεται ο scraper για να εκτελέσει συγκεκριμένες λειτουργίες.
Εάν θέλουμε να τεστάρουμε τον scraper και να δούμε τα δεδομένα που κατέβηκαν πριν να τρέξουμε όλη τη διαδικασία (που μπορεί να πάρει πολύ χρόνο), προσθέτουμε μια οδηγία όπως: «Scrape only the first two pages for testing / Άντλησε δεδομένα μόνο από τις δύο πρώτες σελίδες για δοκιμή».
4. Δημιουργία πολλών scrapers για μια βάση δεδομένων με πολλαπλά επίπεδα
Οι περισσότερες διαδικτυακές βάσεις δεδομένων οργανώνουν τα δεδομένα σε πολλά επίπεδα σελίδων. Στη βάση με τις προμήθειες του Σάο Πάολο, αφού πάρεις τη λίστα με τις προκηρύξεις, κάνεις κλικ στο Objeto (αντικείμενο) κάθε προκήρυξης, για να ανοίξει μια νέα σελίδα με το περιεχόμενό της. Σε κάθε σελίδα προκήρυξης μπορεί να υπάρχει ένα ή περισσότερα Evento (γεγονότα). Στη συνέχεια, κάνεις κλικ στο Detalhes (λεπτομέρειες) για κάθε Evento για να δεις το περιεχόμενό του. Γι’ αυτό μπορεί να χρειαστούν δύο ακόμα scrapers: ένας για να αντλήσει δεδομένα από κάθε σελίδα προκήρυξης και ένας για κάθε σελίδα Evento. Υπάρχει η δυνατότητα συνδυασμού και των τριών σε ένα script, αλλά αυτό είναι λίγο πιο πολύπλοκο. Οι αρχάριοι είναι καλύτερο να χωρίζουν τη διαδικασία σε μικρότερες εργασίες.
Στην περίπτωσή μας, φτιάξαμε πρώτα έναν scraper για να εξάγουμε τα αποτελέσματα της αναζήτησης, συμπεριλαμβανομένων των URL κάθε προκήρυξης. Στη συνέχεια, δώσαμε αυτή τη λίστα URL σε δεύτερο scraper, που επισκεπτόταν κάθε σελίδα προκήρυξης για να αντλήσει το περιεχόμενό της και τα URL των Eventos της. Τέλος, δημιουργήσαμε έναν τρίτο scraper που επισκεπτόταν κάθε σελίδα Evento, εξήγαγε το περιεχόμενο και έψαχνε για λέξεις-κλειδιά όπως «cação», «pescado» και «peixe», για να καθορίσει εάν η προκήρυξη αφορούσε κρέας καρχαρία.

Δεν είναι όλες οι ιστοσελίδες φτιαγμένες, όμως, με τον ίδιο τρόπο, πράγμα που σημαίνει ότι τα prompts που προτείνουμε εδώ μπορεί να μη λειτουργήσουν σωστά στις ιστοσελίδες που σας ενδιαφέρουν, χωρίς κάποιες αλλαγές στο περιεχόμενό τους. Το πλεονέκτημα των LLM είναι ότι μπορούν να αντιμετωπίζουν σφάλματα, να προτείνουν διορθώσεις και να ενσωματώνουν αυτές τις αλλαγές στα scripts. Συχνά ανταλλάσσουμε αλλεπάλληλα μηνύματα με το ChatGPT, για να χειριστούμε πιο σύνθετες σελίδες.
5. Συχνές στρατηγικές παράκαμψης του μπλοκαρίσματος
Πλέον έχετε καταλάβει τι χρειάζεται για να φτιάξετε τους πρώτους σας scrapers και να αρχίσετε να συλλέγετε συστηματικά πληροφορίες από το διαδίκτυο. Κάποια στιγμή, όμως, δοκιμάζοντας ένα καινούριο site ή τρέχοντας συχνά τον ίδιο scraper, μπορεί να βρεθείτε σε αδιέξοδο. Ο κώδικας θα είναι σωστός, θα έχετε βρει τα σωστά HTML στοιχεία και όλα θα δείχνουν εντάξει, αλλά ο server θα εμφανίζει ένδειξη σφάλματος.
Εάν δείτε «Απαγορευμένο/Forbidden», «Μη εξουσιοδοτημένη πρόσβαση/Unauthorized», «Πάρα πολλά αιτήματα/Too Many Requests» ή κάτι παρόμοιο, πιθανότατα ο scraper έχει μπλοκαριστεί. Μπορείτε να ρωτήσετε το LLM τι σημαίνει ακριβώς το κάθε σφάλμα. Σε γενικές γραμμές, τα περισσότερα sites δεν είναι φτιαγμένα για scraping και οι προγραμματιστές συχνά ενσωματώνουν μηχανισμούς παρεμπόδισης. Παρακάτω θα βρείτε τρεις συνηθισμένους τύπους μπλοκαρίσματος και στρατηγικές που μπορείτε να εφαρμόσετε. Η λίστα δεν περιλαμβάνει όλες τις διαθέσιμες επιλογές. Συχνά απαιτείται εξατομικευμένη λύση. Αποτελεί, ωστόσο, έναν πρακτικό οδηγό.
Παρακάτω θα βρείτε τρεις συνηθισμένους τύπους μπλοκαρίσματος και στρατηγικές που μπορείτε να εφαρμόσετε. Η λίστα δεν περιλαμβάνει όλες τις διαθέσιμες επιλογές. Συχνά απαιτείται εξατομικευμένη λύση. Αποτελεί, ωστόσο, έναν πρακτικό οδηγό.
Μπλοκάρισμα λόγω γεωγραφικής τοποθεσίας
Ορισμένα sites περιορίζουν την πρόσβαση ανά χώρα ή περιοχή. Για παράδειγμα, μια κυβερνητική υπηρεσία μπορεί να δέχεται μόνο συνδέσεις από τοπικές IP διευθύνσεις. Σε αυτήν την περίπτωση, μπορείτε να χρησιμοποιήσετε ένα VPN (π.χ. Proton VPN ή NordVPN) ώστε να έχετε τοπική IP. Με αυτόν τον τρόπο, ενώ βρίσκεστε στη Γαλλία, μπορείτε να εμφανίζεστε σαν να συνδέεστε από την Αργεντινή.
Κάποια sites εντοπίζουν την κίνηση από VPN ή μπλοκάρουν γνωστά εύρη διευθύνσεων VPN, οπότε η χρήση VPN ενδέχεται να μη λειτουργήσει. Τότε, μπορείτε να δοκιμάσετε έναν residential proxy (π.χ. Oxylabs), ο οποίος δρομολογεί τα αιτήματα μέσω πραγματικών οικιακών IP και μειώνει σημαντικά την πιθανότητα εντοπισμού.
Μπλοκάρισμα λόγω συχνότητας αιτημάτων
Εάν ο scraper στέλνει πολλά αιτήματα σε μικρό χρονικό διάστημα, ο ιστότοπος μπορεί να τα θεωρήσει αυτοματοποιημένη δραστηριότητα, καθώς δεν μοιάζει με συνηθισμένη ανθρώπινη χρήση. Μπορούμε, λοιπόν, να προσθέσουμε τυχαίες καθυστερήσεις στον κώδικα (π.χ. με τη συνάρτηση time.sleep(seconds) της Python). Επίσης βοηθά η προσομοίωση κινήσεων του ποντικιού και το σκρολάρισμα στη σελίδα, ώστε η συμπεριφορά να φαίνεται πιο «ανθρώπινη». Ένα LLM μπορεί να προτείνει την καλύτερη λύση ανάλογα με το περιβάλλον εκτέλεσης.
Ακόμη και με καθυστερήσεις, ο ιστότοπος μπορεί να μπλοκάρει τη διεύθυνση IP μετά από έναν αριθμό αιτημάτων. Σε αυτήν την περίπτωση προτείνεται η εναλλαγή IP μέσω ρυθμισμένου VPN μέσα από τον κώδικα (π.χ. ProtonVPN + Tunnelblick + tunblkctl) ή, πιο απλά, η χρήση residential proxy που κάνει αυτόματα εναλλαγή IP μέσα από μια μεγάλη «δεξαμενή» οικιακών IP.
Μπλοκάρισμα λόγω εντοπισμού bot
Όταν επισκεπτόμαστε έναν ιστότοπο, ο browser στέλνει κάποιες πληροφορίες «παρασκηνιακά» – αυτές μπορεί να λένε, για παράδειγμα, «είμαι Chrome σε Mac», «η γλώσσα μου είναι τα αγγλικά» – καθώς και μικρά αρχεία που λέγονται cookies. Αυτές οι πληροφορίες ονομάζονται HTTP headers. Ένας απλός scraper συνήθως τα παραλείπει ή τα μιμείται πρόχειρα, κάτι που φαίνεται ύποπτο. Για να περάσει απαρατήρητος, χρειάζεται να συμπεριφέρεται όσο γίνεται σαν κανονικός browser: να ορίζει ρεαλιστικά HTTP headers (π.χ. ένα πειστικό User-Agent και Accept-Language), ένα συνηθισμένο μέγεθος οθόνης (viewport) και, όπου απαιτείται, έγκυρα cookies.
Ένα βασικό prompt για να ρυθμίσει τα παραπάνω ένα LLM θα ήταν:
Below is the script for a Python scraper collecting information from the web page xxx. Provide a basic configuration for HTTP headers and cookies to minimize detection or blocking, and show where to add them in my code.
Παρακάτω είναι το script ενός Python scraper που συλλέγει δεδομένα από τη σελίδα xxx. Φτιάξε μου μια βασική διαμόρφωση για HTTP headers και cookies ώστε να μειώσω τις πιθανότητες ανίχνευσης ή μπλοκαρίσματος, και δείξε μου πού πρέπει να τα προσθέσω στον κώδικά μου. [επικόλληση ολόκληρου του script]
Το LLM θα γράψει τις παραμέτρους που πρέπει να τοποθετηθούν στην αρχή του script.
Επίσης μπορούμε να ενεργοποιήσουμε ή να απενεργοποιήσουμε μια παράμετρο ώστε ο scraper να τρέχει σε headless mode (χωρίς να εμφανίζεται παράθυρο) ή σε headed mode (με κανονικό παράθυρο). Είναι πραγματικά απολαυστικό να βλέπεις τον Chrome να κάνει μόνος του κλικ στη λειτουργία με παράθυρο. Ταυτόχρονα, είναι πιο εύκολο να διορθώσεις σφάλματα (debug) γιατί βλέπεις τα κλικ, τα σφάλματα και τα αναδυόμενα παράθυρα. Είναι, όμως, πιο αργό και καταναλώνει περισσότερη μνήμη και CPU. Το headless mode είναι πιο ελαφρύ και πιο γρήγορο, αλλά συχνά εντοπίζεται πιο εύκολα από τους ιστότοπους. Καλό είναι πρώτα να αναπτυχθεί και να δοκιμαστεί το πρόγραμμα σε λειτουργία με παράθυρο (headed mode) και στη συνέχεια να περάσει σε λειτουργία χωρίς παράθυρο (headless) για πλήρη εκτέλεση.
Οι παραπάνω στρατηγικές αποτελούν μόνο ένα σημείο εκκίνησης. Αν ο scraper εξακολουθεί να μπλοκάρεται, κάνουμε αντιγραφή του μηνύματος σφάλματος και επικόλληση στο LLM για να πάρουμε περισσότερες πληροφορίες για το πώς να το διορθώσουμε.
6. Προχωρημένο scraping: Προγραμματισμός του scraper
Μερικές φορές μπορεί να χρειαστεί να εκτελέσετε τον scraper σε προγραμματισμένο χρόνο — για παράδειγμα όταν μια σελίδα προσθέτει ή αφαιρεί συχνά πληροφορίες και πρέπει να παρακολουθείτε τις αλλαγές. Μπορείτε να τρέχετε τον scraper χειροκίνητα κάθε μέρα, αλλά αυτό είναι κουραστικό και συχνά οδηγεί σε λάθη.
Μια πιο πρακτική λύση είναι η χρήση ενός εργαλείου που τον εκτελεί αυτόματα σε καθορισμένα διαστήματα. Το GitHub Actions είναι μια πολύ χρήσιμη (και δωρεάν) πλατφόρμα για την εκτέλεση εργασιών στο cloud. Το βασικό πλεονέκτημα είναι ότι ο υπολογιστής δεν χρειάζεται να είναι ανοιχτός, καθώς όλα τρέχουν σε μια εικονική μηχανή στο διαδίκτυο.
Αν είστε εξοικειωμένοι με το GitHub, το οποίο είναι μια πλατφόρμα για αποθήκευση κώδικα και συνεργασία με τρίτους πάνω στο λογισμικό, μπορείτε να ανεβάσετε τον scraper στο repository/χώρο αποθήκευσης του κώδικα, να δημιουργήσετε ένα αρχείο .yml και να χρησιμοποιήσετε το YAML για να ρυθμίσετε την εικονική μηχανή και να καθορίσετε τα βήματα εκτέλεσης.
Μπορείτε ξανά να ζητήσετε τόσο τα βήματα όσο και το YAML script από ένα LLM. Ένα παράδειγμα εντολής για να ξεκινήσετε είναι το εξής:
I have a Python scraper in xxxx.py inside the xxxx repository of my GitHub account. I want to use GitHub Actions to run it once a day at 1 PM UTC. Tell me the steps and the YAML code I need to configure it. This is the source code for my scraper: [paste the full scraper script]
Έχω έναν Python scraper στο αρχείο xxxx.py μέσα στο repository xxxx στον λογαριασμό μου στο GitHub. Θέλω να χρησιμοποιήσω το GitHub Actions για να τρέχει μία φορά την ημέρα, στις 13:00 UTC. Δώσε μου τα βήματα και τον κώδικα YAML που χρειάζομαι για να το ρυθμίσω. Αυτός είναι ο πηγαίος κώδικας του scraper μου: [επικόλληση του πλήρους script]
Με τα βήματα, τα παραδείγματα και τα prompts που περιγράφονται παραπάνω, ελπίζουμε ότι αυτός ο οδηγός θα βοηθήσει δημοσιογράφους που δεν διαθέτουν γνώσεις προγραμματισμού να αξιοποιήσουν τα LLMs, για να δουλεύουν ταχύτερα και πιο έξυπνα. Για οποιαδήποτε ερώτηση ή σχόλιο, μπορείτε να επικοινωνήσετε μαζί μας στα [email protected] και [email protected].

